Avec ce système et via les règles DRS, en cas de crash d’un ESX sur le secondary, la VM va redémarrer sur un des ESX du site. En cas de crash complet du site secondary, les VM vont démarrer sur le primary.
On va vérifier par la pratique !!
On valide les informations de la VM et de l’état du VSAN
Les disques sont bien configurés et sécurisés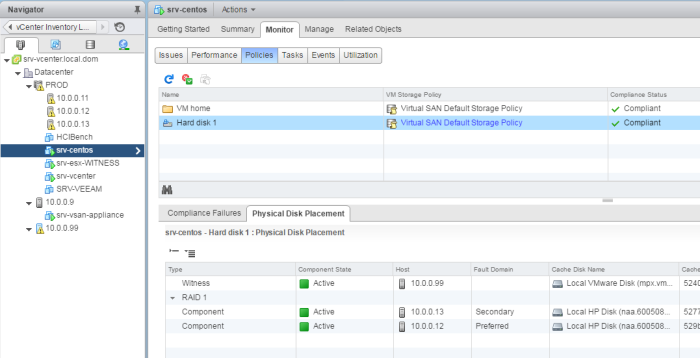
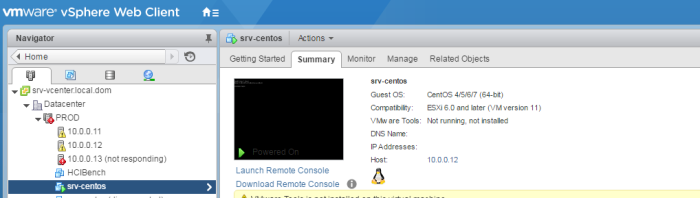
La VM s’éxécute bien sur le serveur SRV-ESX3 (10.0.0.13)
Le VSAN est en bonne santé et le streched cluster est OK
On coupe l’alimentation de SRV-ESX3
Le serveur passe HS, la VM srv-centos continuera de fonctionner sur un des ESX restant.
Attention, on obtient le même résultat que lors du déclenchement du HA, la VM REDEMARRE, on n’est pas en Fault Tolerance !!!
Niveau santé du VSAN, ca coince un peu !!!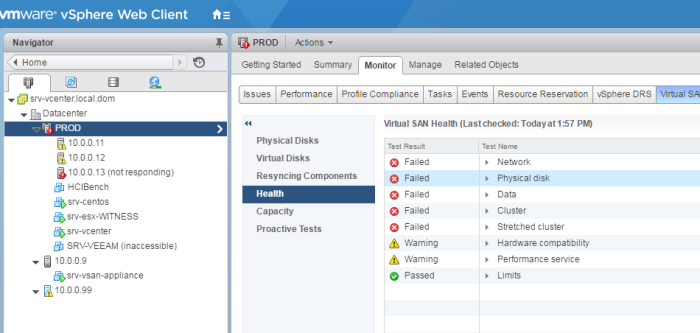
Coté Streched Cluster, on constate bien que le site Secondary n’est plus là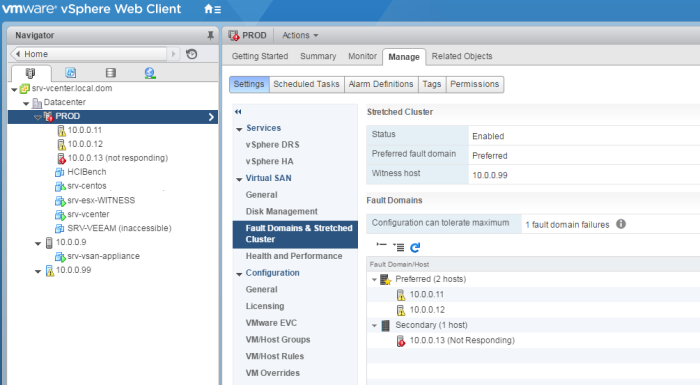
—————————————————–
Ceci termine l’ensemble de labs sur le VSAN
On a vu les concepts de base du VSAN et du mode Streched Cluster
J’ai encore une préférence pour les infrastructures classiques, mais
le Software Defined Storage va très vite se développer avec les offres
hyperconvergées style Vxrail…
—————————————————–
